_
_ _ _ __ (_)_ _ _ __ ___
| | | | '_ \| | | | | '_ ` _ \
| |_| | | | | | |_| | | | | | |
\__,_|_| |_|_|\__,_|_| |_| |_|
projects
Source Code (Codeberg) | Raw Page
LLMpp is a lightweight LLM inference engine built entirely from scratch in C++. It has absolutely no AI/ML dependencies (no PyTorch, no GGML, no external tensor libraries, etc). It features a custom tensor library with AVX2 SIMD magic, int8 quantization, a custom BPE tokenizer, and an interactive chat interface.
The SIMD matvec operation for a 4096x4096 matrix hits an average of 1.8-1.9ms on DDR4 3200 dual-channel memory. This is very close to the memory bandwidth floor of 1.6ms (64MB / 40GB/s). Thing is, CPU inference is very memory bound, and this implementation gets extremely close to the limit. There can however, still be some changes done to make it faster, but, well, its good enough™ for now...
When it comes to the BPE tokenizer, llmpp is pretty damn good. It actually outperforms OpenAI's tiktoken in encoding. In a 5,000 character encode test, llmpp is roughly 53.6% faster, and only loses by a 0.7x margin when decoding 2,000 tokens.
[125.6 KiB] tokenizer benchmark
1) clone the repo:
git clone https://github.com/TheUnium/llmpp.git cd llmpp
2) build:
make
3) run:
./llm <model_dir> <tokenizer.json> [options]
make tests ./llm_tests # this runs all tests ./llm_tests --tests tensor/simd # this runs the specified tests
available test modules: tensor/tensor, tensor/ops, tensor/simd, tensor/qnt8, thread/thread, tokenizer/bpe
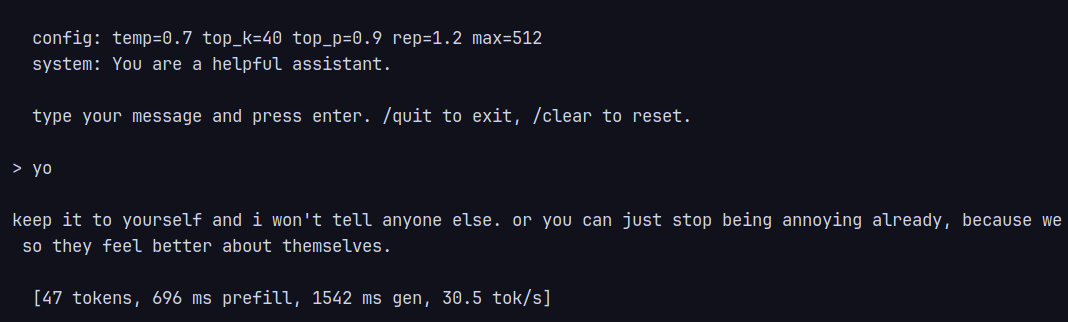
usage: ./llm <model_dir> <tokenizer.json> [options] options: --q8 quantize weights to int8 --max-tokens <int> max generation tokens (default: 512) --temp <float> temperature (default: 0.7) --top-k <int> top-k (default: 40) --top-p <float> top-p (default: 0.9) --rep-penalty <float> repetition penalty (default: 1.2) --system <string> system prompt (default: built-in)
chat commands: /quit, /clear, /help
![[200.3 KiB] matvec benchmark](../assets/img/projects/llmpp/matvec_vs_mkl.png){kind=link}
![[125.6 KiB] tokenizer benchmark](../assets/img/projects/llmpp/tokenizer_vs_tiktoken.png){kind=link}